Research Highlights
Rim-to-Disc Ratio Outperforms Cup-to-Disc Ratio for Glaucoma Prescreening
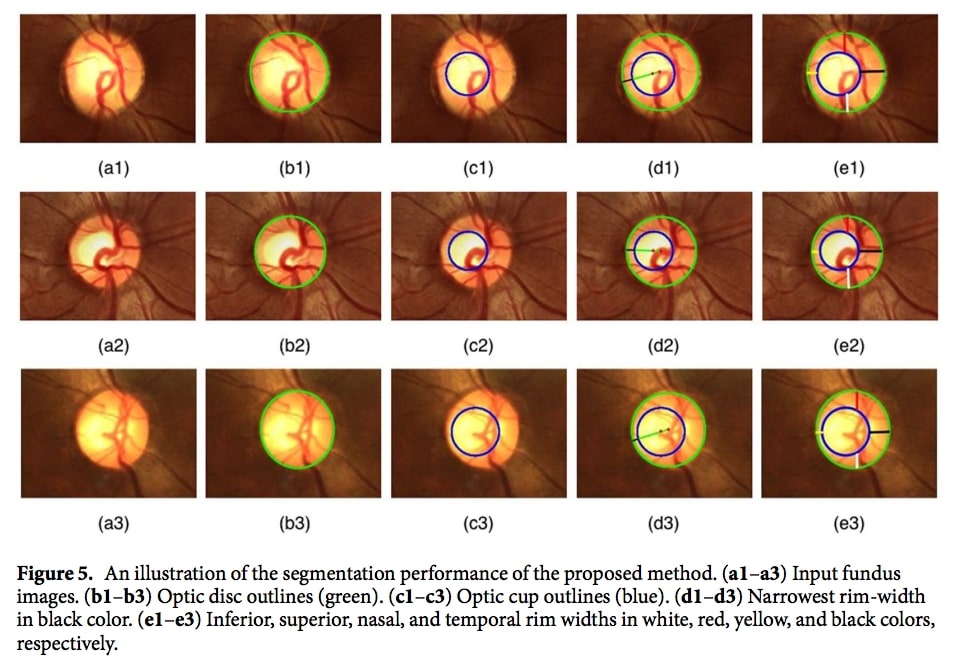
We developed a novel and fully automated fundus image processing technique for glaucoma prescreening based on the rim-to-disc ratio (RDR). The technique accurately segments the optic disc and optic cup and then computes the RDR based on which it is possible to differentiate a normal fundus from a glaucomatous one. The technique performs a further categorization into normal, moderate, or severely glaucomatous classes following the disc-damage-likelihood scale (DDLS). To the best of our knowledge, this is the first engineering attempt at using RDR and DDLS to perform glaucoma severity assessment. The segmentation of the optic disc and cup is based on the active disc, whose parameters are optimized to maximize the local contrast. The optimization is performed efficiently by means of a multiscale representation, accelerated gradient-descent, and Green’s theorem. Validations are performed on several publicly available databases as well as data provided by manufacturers of some commercially available fundus imaging devices. The segmentation and classification performance is assessed against expert clinician annotations in terms of sensitivity, specificity, accuracy, Jaccard, and Dice similarity indices. The results show that RDR based automated glaucoma assessment is about 8% to 10% more accurate than a cup-to-disc ratio (CDR) based system. An ablation study carried out considering the ground-truth expert outlines alone for classification showed that RDR is superior to CDR by 5.28% in a two-stage classification and about 3.21% in a three-stage severity grading.
Reference: https://www.nature.com/articles/s41598-019-43385-2.pdf
Knowledge-driven training of deep models for better reconstruction and recognition
Knowledge-driven training of deep models for better reconstruction and recognition Every deep learning-based model works well for a particular task. The current trend is to design and develop models with more width and depth of the neural network to obtain better results, which requires huge training costs. A study conducted by OpenAI in 2018 found that the computing power needed to train AI is rising seven times faster than ever before. This may be unsustainable. In the MILE lab, we have shown that it is possible to reduce training costs(and save energy), while achieving state of the art results, by deploying appropriate core image processing and computer vision techniques to modify the models at three different levels: input, architecture, and objective function. We have demonstrated the efficacy of this approach in various computer vision and image processing tasks.
Reconstruction of document and natural images using deep neural network: We use knowledge to train deep models efficiently and reduce the number of learnable parameters. Figure (a) shows the result obtained on a sample highly degraded binary document image. Our technique fills in most of the missing pixels, and the reconstructed output has better readability and a significantly increased OCR (character level) accuracy. Figure (b) shows that the perceptual quality of the images generated by our methods is better than that of the state-of-the-art technique, SRGAN.
Patent filed: R K Pandey and A G Ramakrishnan, ``Device and method for enhancing readability of a low-resolution binary image," Patent Application No. E-2/3249/2019/CHE.
Facial Emotion Recognition: We have extended our knowledge-driven training to the challenging task of facial emotion recognition (FER) and improved the performance of the best networks in the literature by 3 to 5%. In another experiment, we reduced the number of parameters by a factor 24, while achieving state-of-the-art results.
Mean Square Canny loss function: We have proposed this edge-preserving loss function, which improves the performance of state-of-the-art networks in both superresolution and denoising tasks. Further, we have improved the FER performance by using a combination of center loss and softmax loss functions.
Image Style transfer: In this work, we have shown that the core techniques can also be applied to the task of image style transfer to obtain computationally efficient deep learning models.

Network Consistent Data Association
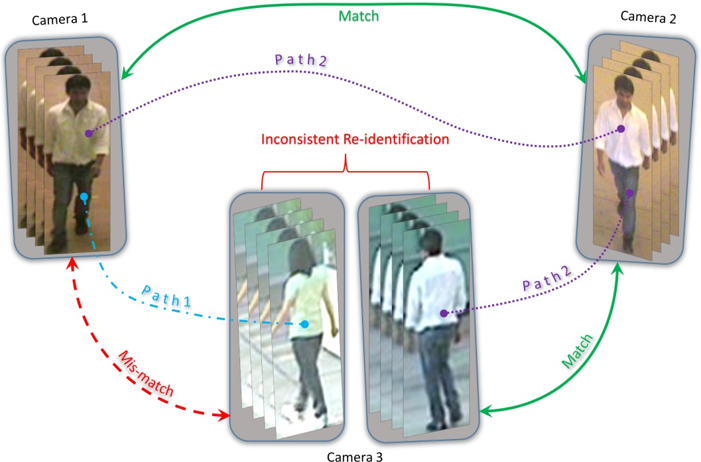
Existing data association techniques mostly focus on matching pairs of data-point sets and then repeating this process along space-time to achieve long term correspondences. However, in many problems such as person re-identification, a set of data-points may be observed at multiple spatio-temporal locations and/or by multiple agents in a network and simply combining the local pairwise association results between sets of data-points often leads to inconsistencies over the global space-time horizons. In this research project, we proposed a novel Network Consistent Data Association (NCDA) framework formulated as an optimization problem that not only maintains consistency in association results across the network, but also improves the pairwise data association accuracies. The proposed NCDA can be solved as a binary integer program leading to a globally optimal solution and is capable of handling the challenging data-association scenario where the number of data-points varies across different sets of instances in the network. We also presented an online implementation of NCDA method that can dynamically associate new observations to already observed data-points in an iterative fashion, while maintaining network consistency.

ChExVis: a tool for molecular channel extraction and visualization
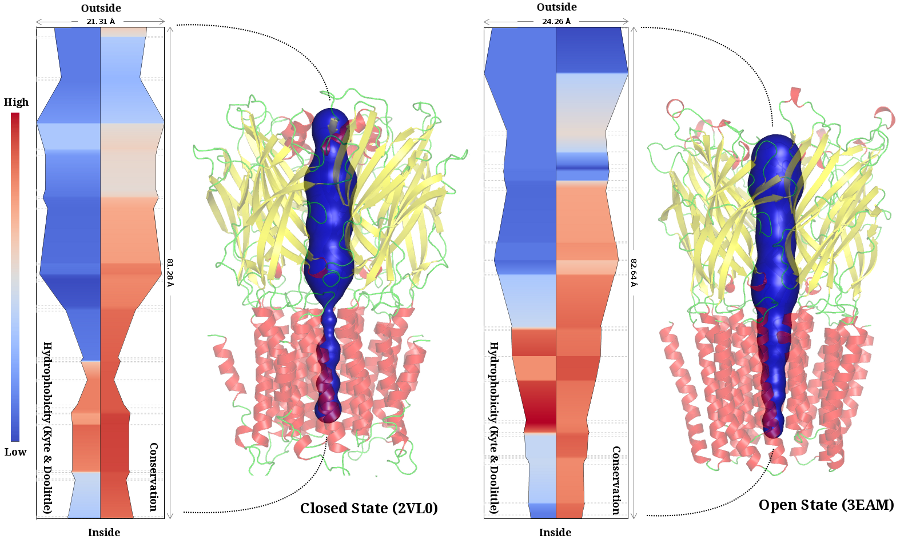
A channel is a pathway through empty space within the molecule. Understanding channels, that lead to active sites or traverse the molecule, is important in the study of molecular functions such as ion, ligand, and small molecule transport. Efficient methods for extracting, storing, and analysing protein channels are required to support such studies. We develop an integrated framework called ChExVis that supports computation of the channels, interactive exploration of their structure, and detailed visual analysis of their properties
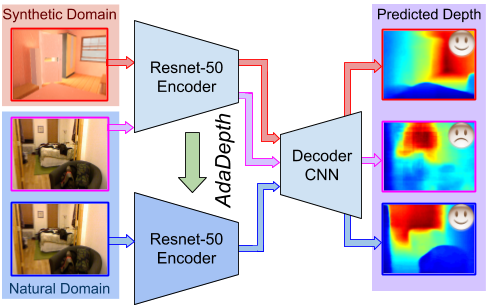
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
Recent
advances in deep learning relies heavily on availability of huge amount of clean annotated information involving substantial manual effort. This becomes a major challenge for tasks related to an entire scene understanding in contrast to a simple object classification
task. Researchers are focusing on efficient techniques to use already available synthetic data from various 3D game engines for training artificial vision systems. But, the key question is: how can we adapt such systems for natural scenes with minimal supervision?
In a recent study by Prof. Venkatesh Babu and his team from Video Analytics Lab, Department of Computational and Data Sciences, have proposed a novel adversarial learning approach to efficiently adapt synthetically trained models for real scene images. The
proposed adaptation method can be used to disentangle the domain discrepancy for improved performance on real scenes from the deployed environment in an unsupervised manner. Currently, the focus is on the task of depth estimation from monocular RGB image scene.
But the approach can be extended to other scene understanding problems as well. The method uses an efficient content consistency regularization along with an adversarial learning objective function to train the base Convolutional Neural Network (CNN) architecture.
Moreover, the proposed regularization helps to efficiently maintain the spatial dependency of deep features with respect to the given input during the adaptation process. This work will be presented at this year's CVPR conference.
Jogendra Nath Kundu, Phani Krishna, Anuj P. and R. Venkatesh Babu, "AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation", in CVPR 2018
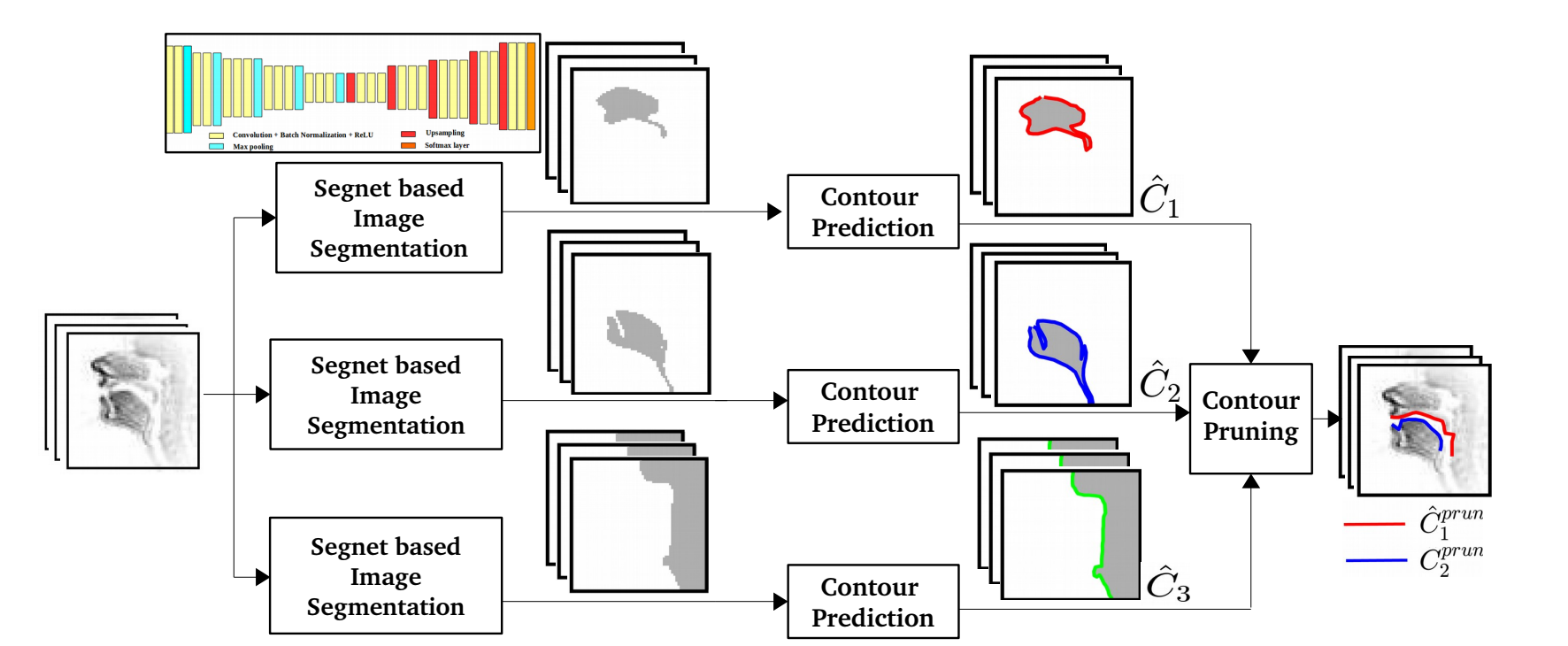
Air-tissue boundary segmentation in real time magnetic resonance imaging video using Segnet
The advancements in the field of speech have inspired researchers to understand the speech production using various tools like Electromagnetic articulograph, Ultrasound, X-Ray and real-time magnetic resonance imaging (rtMRI) are used. The rtMRI has an edge over the other techniques in capturing the complete vocal tract (in the midsagittal plane) in a non-invasive manner, making it an indispensable tool for studying speech production mechanism. The rtMRI videos provide the temporal information of speech articulators that help in understanding the mechanism of speech production, creating augmented video for spoken language training and several other applications related to speech. However, in order to accurately estimate the positions of different articulators or implement a realistic augmented video, it is essential to precisely estimate the air tissue boundaries (ATBs). Semantic segmentation is deployed in the proposed approach using a Deep learning architecture called SegNet. The network processes an input image to produce a binary output image of the same dimensions having classified each pixel as air cavity or tissue, following which contours are predicted. A Multi-dimensional least square smoothing technique is applied to smoothen the contours. To quantify the precision of predicted contours, Dynamic Time Warping (DTW) distance is calculated between the predicted contours and the manually annotated ground truth contour. Four fold experiments are conducted with four subjects from the USC-TIMIT corpus, which demonstrates that the proposed approach achieves a lower DTW distance of 1.02 and 1.09 for the upper and lower ATB compared to the best baseline scheme. The proposed SegNet based approach has an average pixel classification accuracy of 99.3% across all the subjects with only 2 rtMRI videos (~180 frames) per subject for training.
Surveillance Face Recognition and Cross-Modal Retrieval
In the IACV lab, we are looking at different problems in computer vision. Now-a- days with increasing security concerns, surveillance cameras are installed everywhere, from shopping malls, airports, and even in personal homes. One of the main objectives of surveillance is to recognize the facial images captured by these cameras. This is very challenging, since the images usually have quite poor resolution, in addition to uncontrolled illumination, pose and expression. We are developing novel algorithms for matching the low-quality facial images captured using surveillance cameras. This is also extended to general objects as well. We are also working on traffic surveillance, especially for Indian scenarios, like vehicle detection, classification and license plate recognition, etc. Another major area we are looking at is Cross-Modal Matching. Due to increase in the number of sources of data, research in cross-modal matching is becoming an increasingly important area of research. It has several applications like matching text with image, matching near infra-red images with visible images (eg, for matching face images captured during night-time or low-light conditions to standard visible light images in the database), matching sketch images with pictures for forensic applications, etc. We are developing novel algorithms for this problem, which is extremely challenging, due to significant differences between data from different modalities.


Regularization Using Denoising: The Plug-and-Play Paradigm for Inverse Problems.
Description: The quintessential computational problem in imaging modalities such as nuclear magnetic resonance imaging, x-ray tomography, microscopy, etc. is thereconstruction ofhigh-resolution images from physical measurements. Dramatic progress has been made in the last couple of decades producing several powerful ground-truth priors that also yield fast numerical algorithms. Typically, the algorithms are based on iterative methods, where each iteration involves the inversion of the measurement model followed by enforcement of the ground-truth prior. Morerecently, researchers have come up with aningenious means of enforcing priors, namely, the image afterthe inversion (during which artifacts are introduced) is cleaned up using a powerful image denoiser. This so-called plug-and-play paradigm involves the repeated inversion of the measurement model followed by the denoising step. Recently, we have come up with ways of speeding up plug-and-play algorithms (oftenbya couple of orders) using efficient image denoisers[1,2];what would typically take minutes can now be done in few seconds.(joint work with Sanjay Ghosh, UnniVS, and Pravin Nair)
Publications:
[1] P. Nair, V. S. Unni, and K. N. Chaudhury. Hyperspectral image fusion using fast high-dimensional denoising. Proc. IEEE International Conference on Image Processing (ICIP), 2019.
[2] V. S. Unni, S. Ghosh, and K. N. Chaudhury. Linearized ADMM and fast nonlocal denoising for efficient plug-and-play restoration. Proc. IEEE Global Conference on Signal and Information Processing (GlobalSIP), 2018.
.jpg)
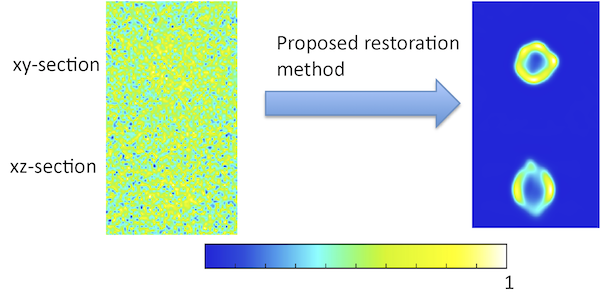
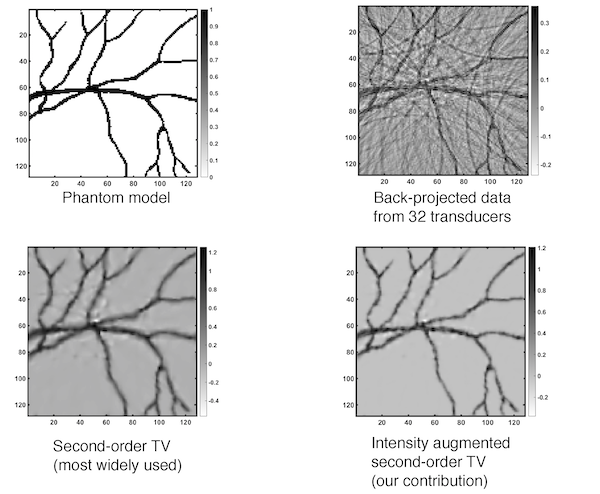
Regularization in Fluorescence Microscopy and Photoacoustic Imaging
Structures imaged by fluorescence microscopy and photo-acoustic imaging (PAT) have a statistical distribution of high intensity and high curvature points that is distinct from the structures imaged under other modalities such as MRI and CT. We constructed a form of regularization functional that combines the image intensity and derivatives in a unique way, to exploit these specific characteristics, and applied it to image deblurring and reconstruction for PAT and fluorescence microscopy. Under the presence of a large amount of noise, we obtained significantly improved restoration/reconstruction compared to well known state-of-the-art regularization techniques.
Quality Assessment of Image Stitching for Virtual Reality
An important element of generating wide field of view images for virtual reality applications involves stitching overlapping camera captured images. It is important to automatically assess the quality of stitched images to benchmark and improve stitching algorithms. We focus on designing quality assessment (QA) models for stitched images as well as validating these through subjective studies. We design the Indian Institute of Science Stitched Image QA database consisting of stitched images and human quality ratings. The database consists of a variety of artifacts due to stitching such as blur, ghosting, photometric, and geometric distortions. We then devise an objective QA model called the stitched image quality evaluator (SIQE) using the statistics of steerable pyramid decompositions. We show through extensive experiments that our quality model correlates very well with subjective scores in our database. The database as well as the software release of SIQE have been made available online for public use and evaluation purposes.







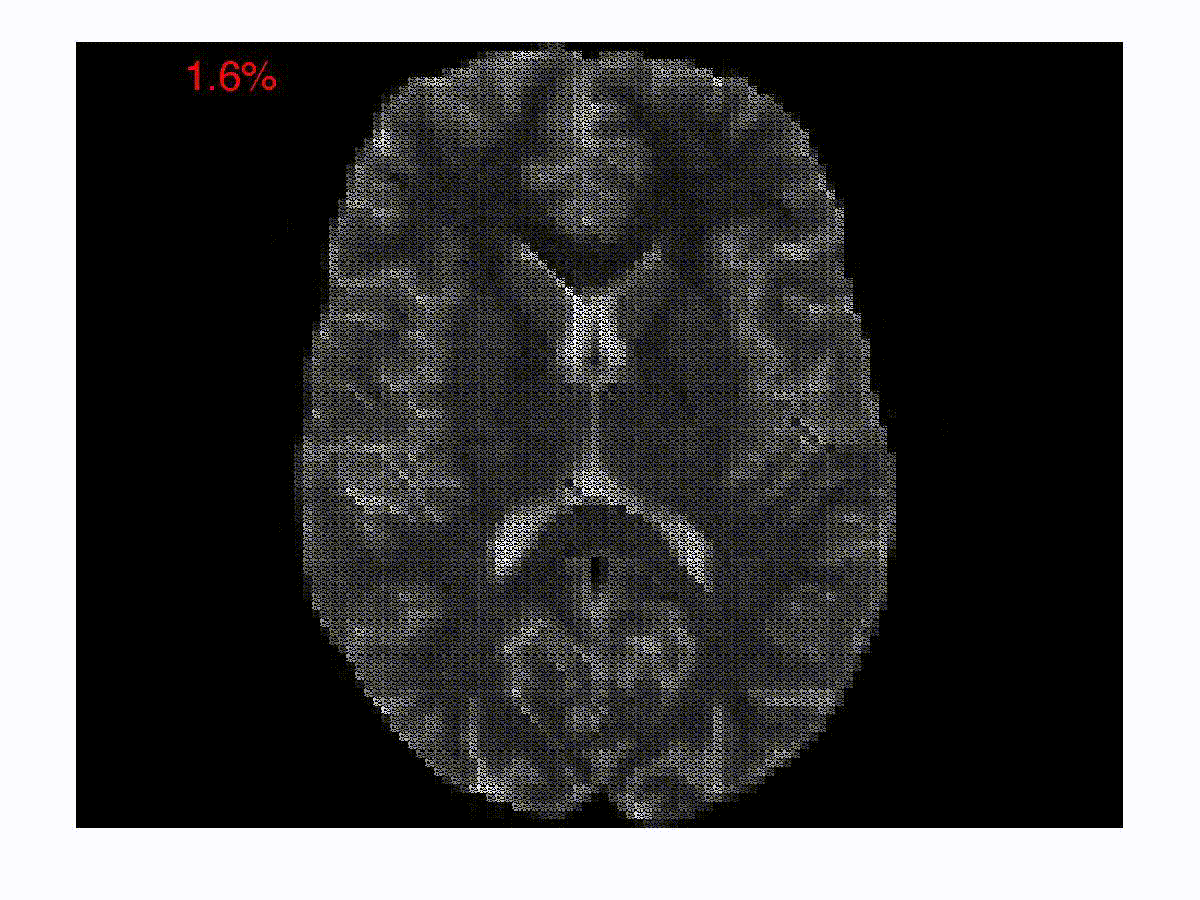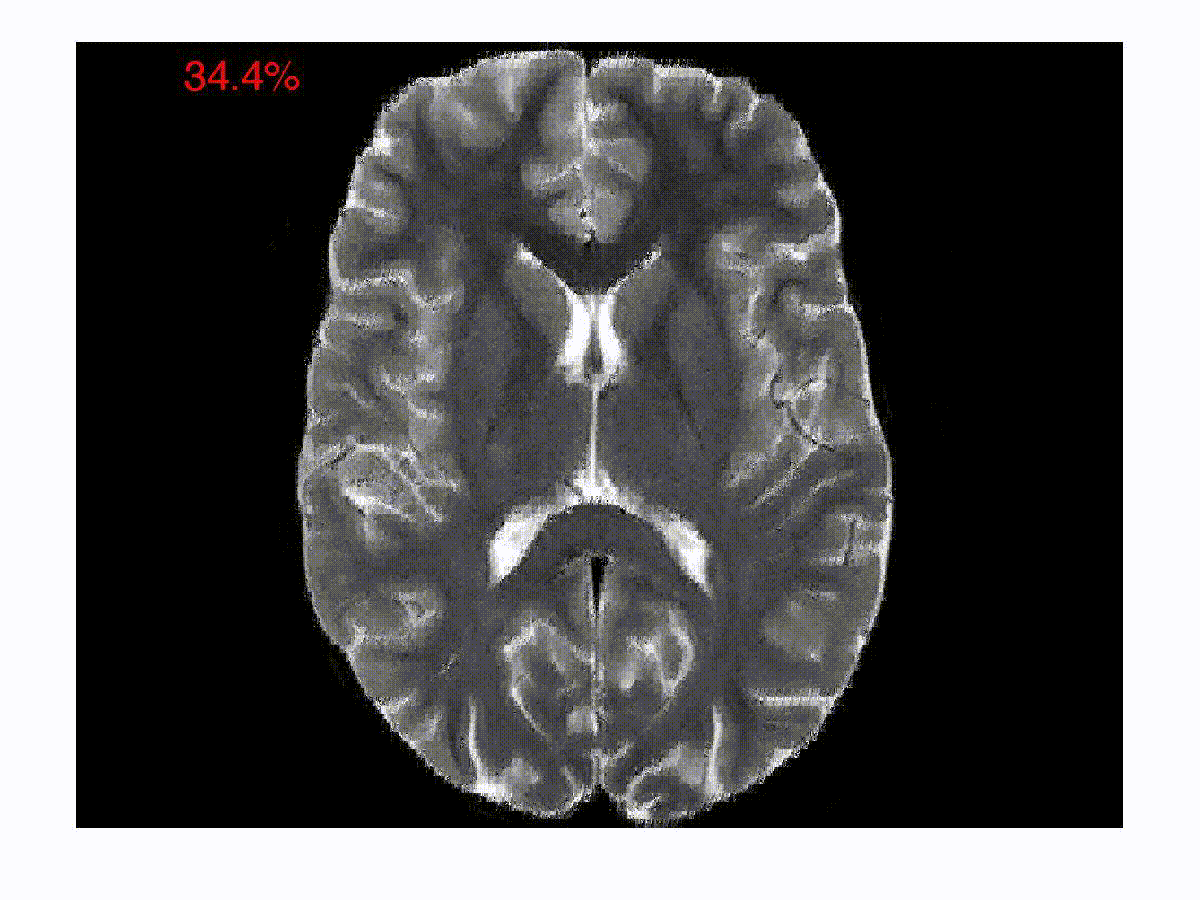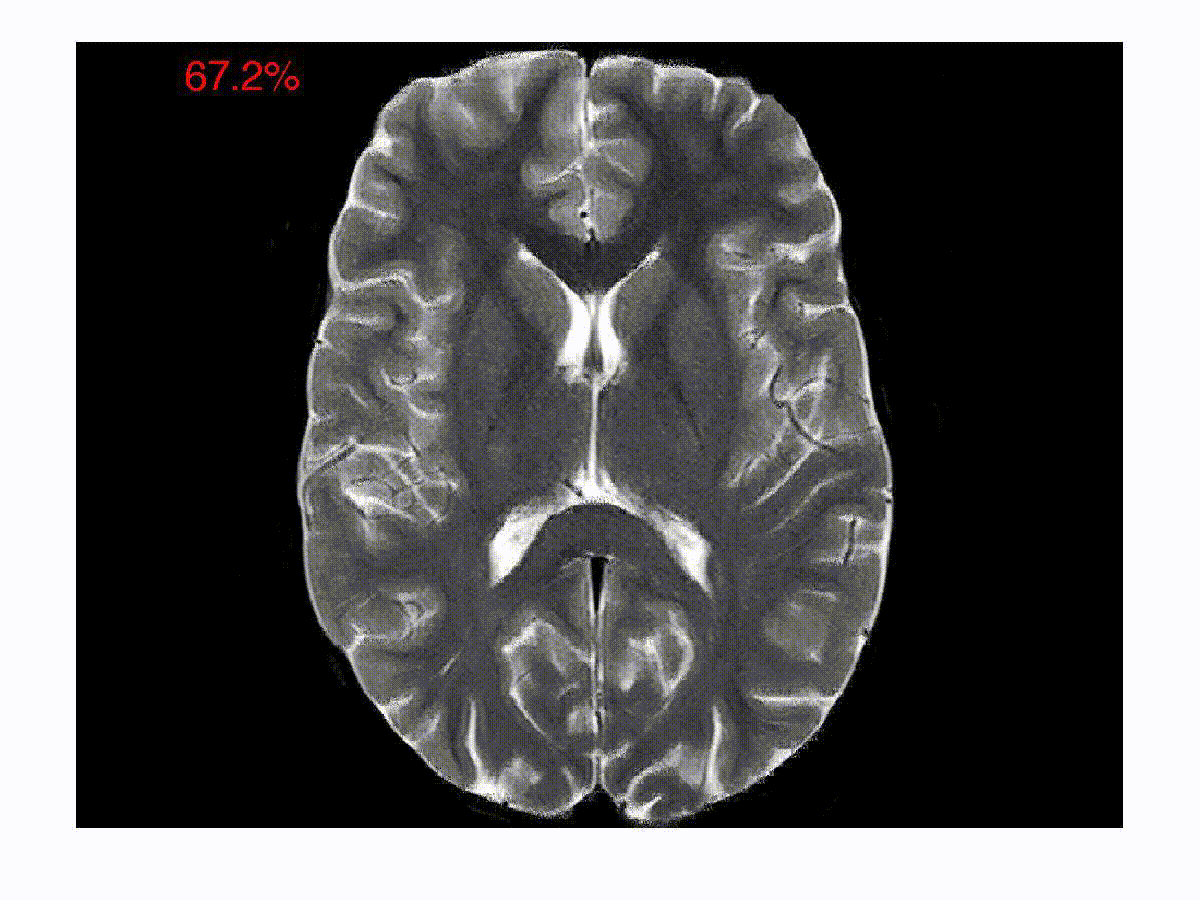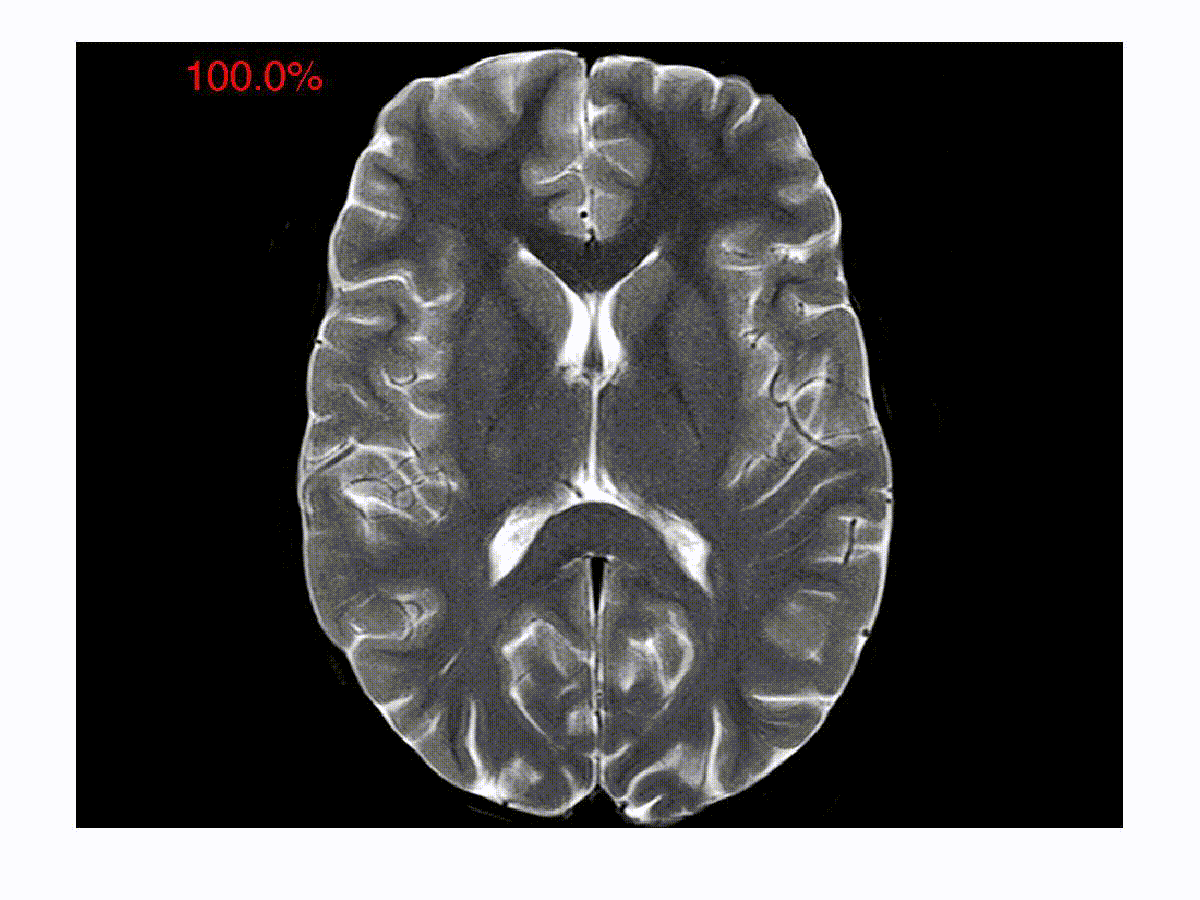
Online Reconstruction Algorithms for Compressed Imaging
One of the focus areas of the Spectrum Lab is in solving inverse problems in imaging and image processing. In a typical compressed imaging application, one acquires projections of a scene on to random test/sensing vectors, which are often binary. In an optical imaging setup, a binary sensing array is essentially an amplitude mask that allows light to go through in some regions and blocks light in the other regions. In a magnetic resonance imaging setup, the sensing vectors are two-dimensional Fourier vectors. The goal in these new imaging modalities is to reconstruct the images from the compressed/encoded measurements. The compression in such a setup happens right at the level of acquisition. The goal is to develop computationally efficient online decoding techniques that sequentially update the reconstruction as the measurements arrive. The reconstruction technique also incorporates priors about the underlying image such as sparsity in an appropriate basis. Such a sequential reconstruction scheme has the advantage that one can stop acquiring measurements as and when the reconstructed image meets a certain objective or subjective quality requirement. We have developed low-complexity online reconstruction techniques that are on par with batch-mode reconstruction techniques in terms of the quality of reconstruction. The images show the reconstructions as the measurements are revealed sequentially. We are currently developing Deep Neural Network (DNN) based image reconstruction schemes that can be fine-tuned to maximize the reconstruction quality for specific imaging settings.
Deep Learning Techniques for Solving Inverse Problems
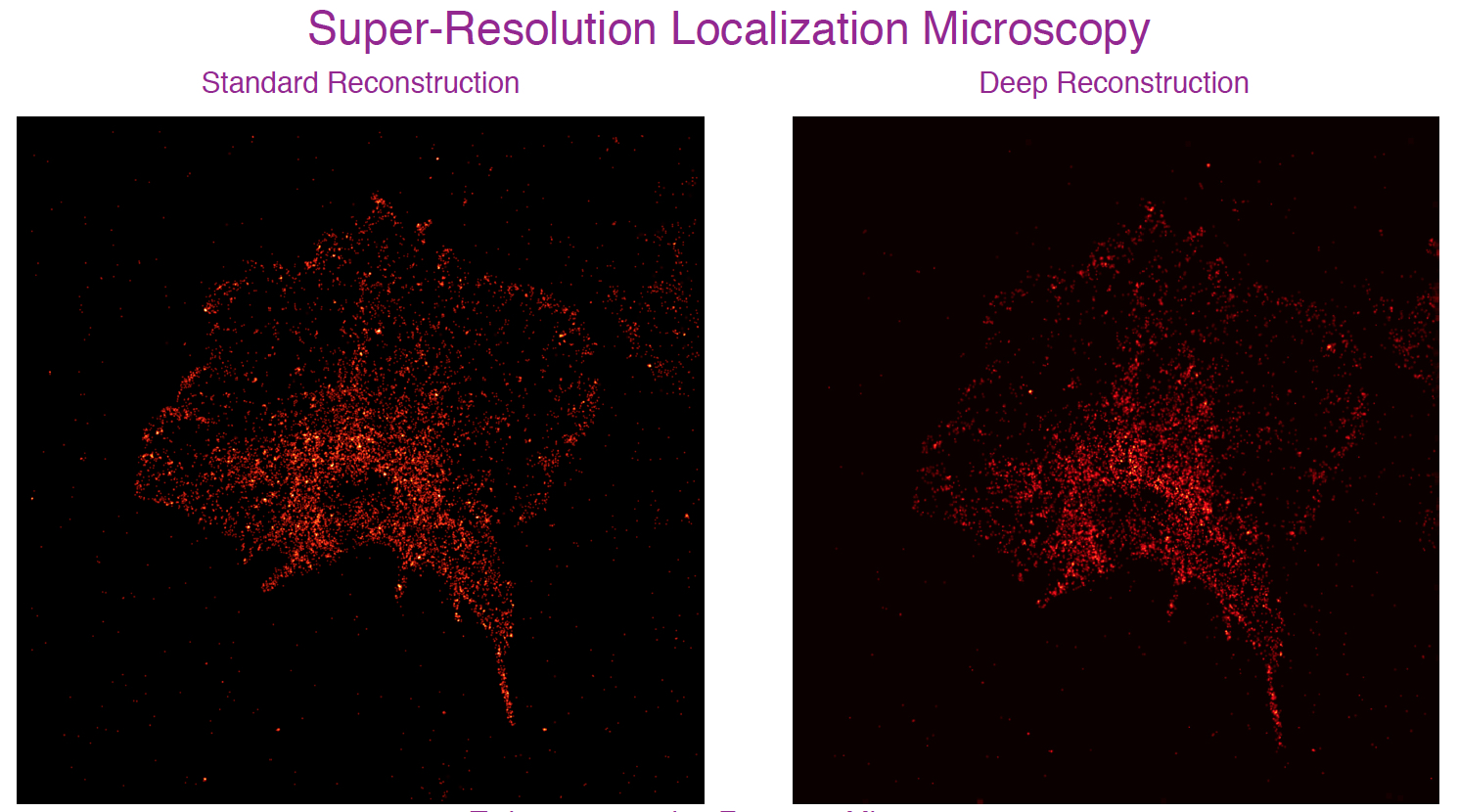
We address the problem of sparse spike deconvolution from noisy measurements within a Bayesian paradigm that incorporates sparsity promoting priors about the ground truth. The optimization problem arising out of this formulation warrants an iterative solution. A typical iterative algorithm includes an affine transformation and a nonlinear thresholding step. Effectively, a cascade/sequence of affine and nonlinear transformations gives rise to the reconstruction. This is also the structure in a typical deep neural network (DNN). This observation establishes the link between inverse problems and deep neural networks. The architecture of the DNN is such that the weights and biases in each layer are fixed and determined by the blur matrix/sensing matrix and the noisy measurements, and the sparsity promoting prior determines the activation function in each layer. In scenarios where the priors are not available exactly, but adequate training data is available, the formulation can be adapted to learn the priors by parameterizing the activation function using a linear expansion of threshold (LET) functions. As a proof of concept, we demonstrated successful spike deconvolution on synthetic dataset and showed significant advantages over standard reconstruction approaches such as the fast iterative shrinkage-thresholding algorithm (FISTA). We also show an application of the proposed method for performing image reconstruction in super-resolution localization microscopy. Effectively, this is a deconvolution problem and we refer to the resulting DNNs as Bayesian Deep Deconvolutional Networks.
Once a DNN based solution to the sparse coding problem is available, one can use it to also perform dictionary learning.
-
Related material:
- Deep Learning Meets Sparse Coding: https://www.youtube.com/watch?v=r3q05c1PIRg
- NIPS 2017 Bayesian Deep Learning Workshop paper on DNNs for Sparse Coding and Dictionary Learning: http://bayesiandeeplearning.org/2017/papers/31.pdf
- NIPS 2017 Bayesian Deep Learning Workshop paper on Bayesian Deep Deconvolutional Networks: http://bayesiandeeplearning.org/2017/papers/46.pdf
- Focus on Microscopy 2018 abstract: http://www.focusonmicroscopy.org/2018/PDF/1213_Seelamantula.pdf
Artificial Intelligence for Healthcare Applications
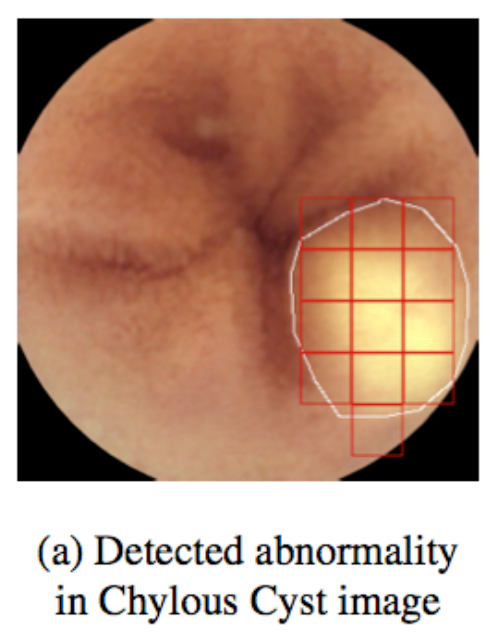
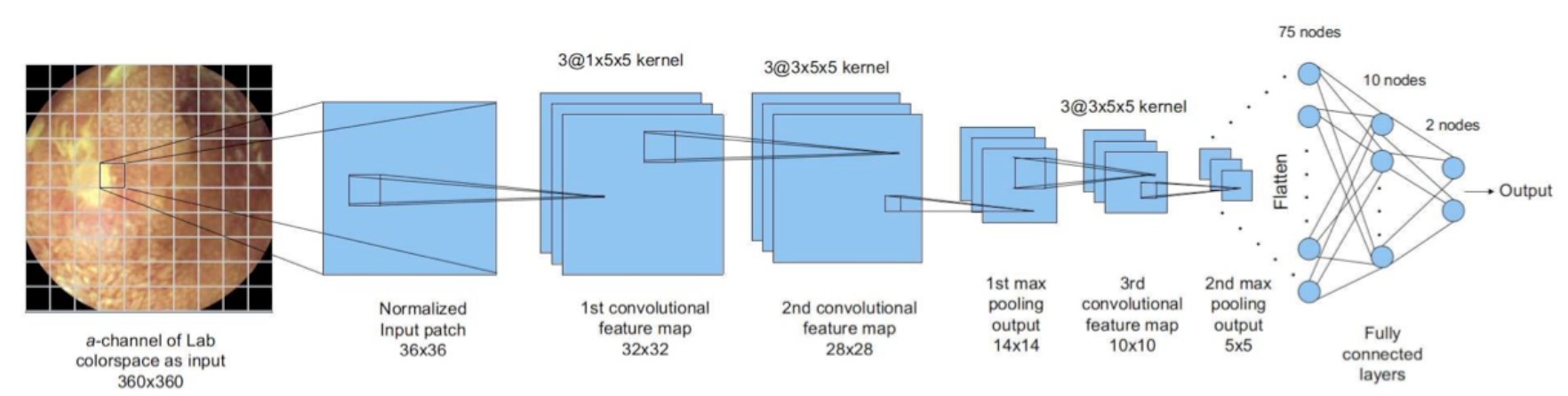
A new focus area of the Spectrum Lab is to develop artificial intelligence systems for healthcare applications. The goal is to develop decision support systems that aid an expert doctor so that best use is made of the specialist’s time and expertise. We developed one such application in the context of wireless capsule endoscopy (WCE), which is a revolutionary approach to performing endoscopy of the entire gastrointestinal tract. In WCE, a patient swallows a miniature capsule-sized optical endoscope and carries a wireless receiver in his pocket. The capsule endoscope transmits several thousands of images as it traverses the gastrointestinal tract. The number of images is huge and sifting through all of them would take considerable time for an expert. In order to alleviate the scanning burden, we have developed an artificial intelligence based decision support system. Effectively, we have a convolution neural network (CNN) that sifts through the images and classifies them as normal or as belonging to one of eight prominent disease types, further highlighting where in the image the abnormality has been detected. This step greatly reduces the burden on the expert and makes efficient use of his/her time. Ongoing effort in this direction is to improve on the CNN architecture and develop hierarchical classification schemes to maximize the classification accuracy.
This project was funded by the Robert Bosch Centre for Cyberphysical Systems (IISc).
-
Related material:
- A convolutional neural network approach for abnormality detection in wireless capsule endoscopy: https://ieeexplore.ieee.org/document/7950698/
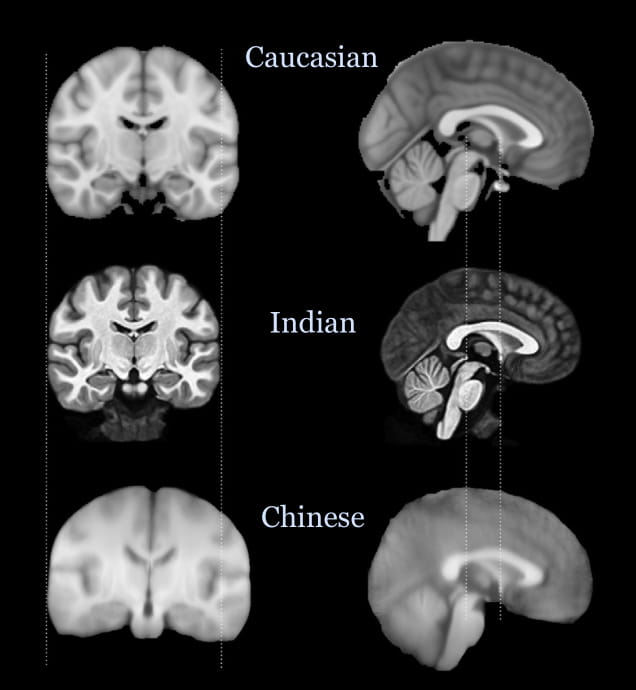
Population Differences in Brain Morphology
Brain templates provide a standard anatomical platform for population based morphometric assessments, used in diagnosis of neurological disorders. Typically, standard brain templates for such assessments are created using Caucasian brains, which may not be ideal to analyze brains from other ethnicities. This study developed first Indian brain template in collaboration with NIMHANS, Bangalore, which is currently being used in assessing Dementia, Schizophrenia, and Bipolar disorders Related publication: Naren Rao, Haris Jeelani, Rashmin Achalia, Garima Achalia, Arpitha Jacob, Rose dawn Bharath, Shivarama Varambally, Ganesan Venkatasubramanian, and Phaneendra K. Yalavarthy, Population differences in Brain morphology: Need for population specific Brain template Psychiatry research: Neuroimaging 265, 1-8 (2017).